Skip to the content.
概要
- 公開日: 2024/11/04
- 機関: Zhejiang University, Institute of Computing Innovation
- リンク
手法
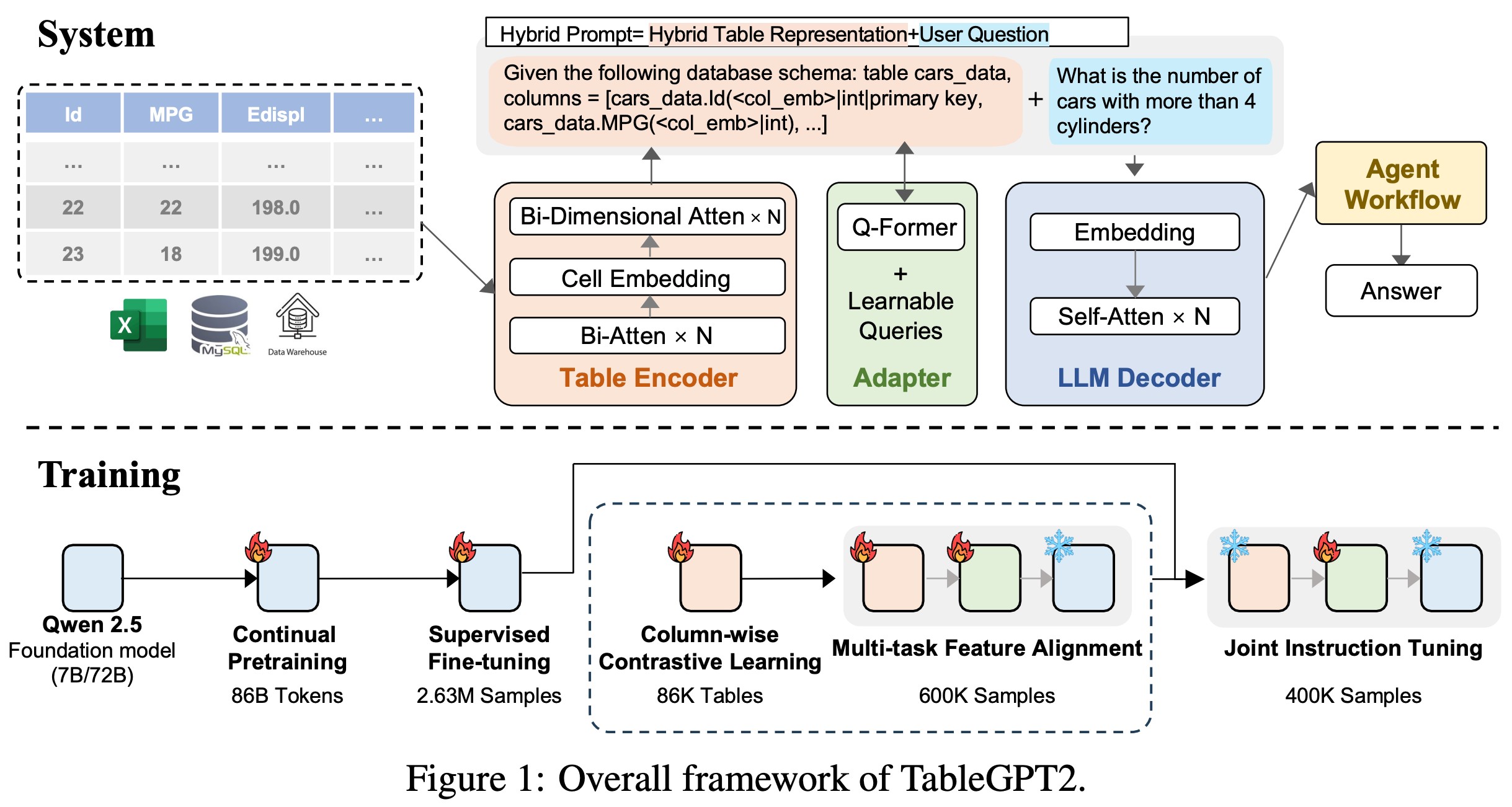
- TableGPT2はQwen-2.5-InstructをベースにしたLLM Decoderに加えて、Table EncoderとAdapterで構成される
- それぞれの学習手順は以下になる。
- LLM Decoder
- Business intelligenceやDBを用いた業務に関係のある文書やコードで継続事前学習を行う
- テキストデータに対する一般的なパフォーマンスを犠牲にせずデータ分析タスクに特化するためのSupervised fine-tuningを行う
- Table Encoder
- Column-wiseの対象学習でテーブルデータだけを用いて事前学習を行う
- Table Encoder + Adapter
- LLM Decoderは学習させず、テーブルに特化したタスク (Column prediction, cell prediction, etc)によってTable EncoderとAdapterを一緒に学習
- Adapter
- Instruction tuningとしてAdapterのみを学習
- Supervised fine-tuning用に学習データ (2.36M QA pairs) を生成している。
- データ収集後、複数のLLMとプロンプトを用いてクエリと答えを生成する。
- クエリと答えの生成後、人間によるチェックが介入する
- Single-turnのQAだけでなく、Multi-turnのQAにも対応している
評価
- 既存ベンチマークだけでなく、より実世界のタスクに向けたRealTabBenchを作成している
- TableGPT2-7BとTableGPT2-72Bがあり、72BがGPT-4oを抑えてトップである。
備考・所感
- TableGPT2-7Bのみhuggingfaceで公開されている。AdapterとTable Encoderは公開されていない。
- TQA-Benchという複数テーブルが絡んだQAタスクで性能評価されているが、微妙な結果になっている。